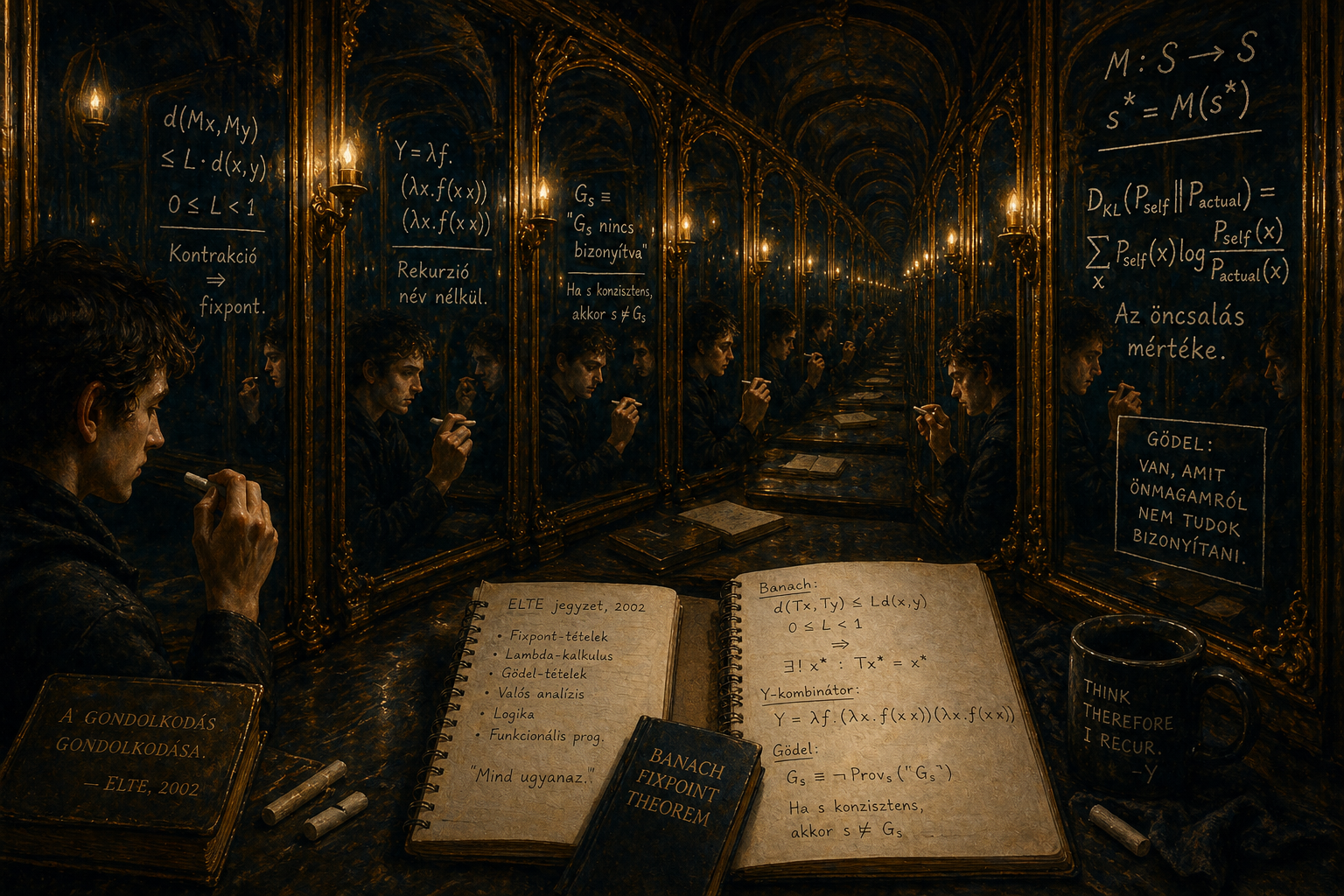
TL;DR
- A metakogníció matematikailag egy operátor: , ahol a mentális állapotok tere.
- Az “elgondolkozni saját magamról” annyit tesz: keresd meg fixpontját. Banach szerint ez akkor és csak akkor egyértelmű, ha kontrakció.
- Ha nem kontrakció — ha az önreflexió erősíti önmagát — kapsz strange loop-ot, divergenciát, vagy káoszt. Sokszor ez ugyanaz, mint az ADHD-roham vagy a depressziós rumináció.
- Gödel azt mutatja: van olyan állítás -ről, amit önmagáról nem tud bizonyítani. A metakogníció nem teljes.
- A Bayes-hierarchia () megadja, mennyit tudsz a saját bizonytalanságodról. Ez a számítási költsége nem nulla — Russell és Wefald 1991-es tétele szerint a meta-gondolkodásnak ára van.
- A KL-divergencia méri, mennyire tér el a saját modelled önmagadról a tényleges állapotodtól. Az “öncsalás” formálisan: .
- Az LLM önreflexió ugyanezekkel a problémákkal küzd: nincs ground truth attention a saját súlyaira.
- A spike.land tézis ennek a következménye: ha a metakogníció önmagán vakfoltos, akkor külső perszonák (Erdős, Einstein, Arendt) szolgálnak meta-szintnek. Egy gráf, amely látja, amit te nem látsz.
Az ELTE-jegyzeteim, 2002 körül
Volt egy hét a programtervező matematikus szakon, amikor három különböző tárgy ugyanazt mondta el más nyelven.
A funkcionális programozás órán Y-kombinátorral csináltunk rekurziót anélkül, hogy a függvény tudná a saját nevét.
A logika előadáson Gödel első nemteljességi tételének vázlatát írtuk fel — egy formula, ami azt mondja önmagáról, hogy “én bizonyíthatatlan vagyok.”
A valós analízis gyakorlaton Banach fixpont-tételét bizonyítottuk: ha kontrakció egy teljes metrikus téren, akkor pontosan egy létezik.
Akkor még nem láttam, hogy ez ugyanaz a tétel három nyelven.
Most — 24 évvel később, miközben naponta nézem, ahogy egy LLM gondolkodik a saját kontextusáról — már látom. És szerintem ez az, amit a metakognicióról matematikailag el lehet mondani.
Ez a poszt egy kísérlet: bevezetni a metakogníciót programtervező matematikusoknak, anélkül, hogy elveszne a misztika és a “tudatosság elmélete” ködeiben.
1. A definíció
A kogníció egy függvény: állapotok és környezet → új állapot.
Itt a mentális állapotok tere (akármi is legyen ez — vegyük absztrakt halmaznak), a környezet.
A metakogníció egy függvény, amelynek bemenete maga .
Magyarul: átalakítja, hogyan gondolkodsz, attól függően, amit a gondolkodásodról észlelsz.
Ez azonnal egy típusparadoxonhoz vezet, ahogy az Russell óta ismert. Ha önmagát is átalakíthatja, akkor . Ez Russell-féle paradoxonszag.
A típuselméleti megoldás: rétegezz.
Minden meta-szint egy magasabb típusban él. Ahogy Hofstadter mondja: a “strange loop” abból ered, hogy a szintek összemosódnak, nem hogy elválnak.
Az emberi agy, sajnos, nem rétegez tisztán. Egy típusrendszer nélküli interpreter vagy. Ezért lehet végtelen ciklusba esni, amikor azon gondolkodsz, hogy gondolkodsz arról, hogy gondolkodsz.
2. A fixpont — Banach módra
Tegyük fel, hogy tisztességes operátor. Mikor van értelme arról beszélni, hogy “önmagamhoz hű” vagyok?
Akkor, ha létezik fixpont: .
Egy állapot, amely a metakognició alkalmazása után változatlan. Ez az, amit a buddhisták “nyugalomnak” hívnak, a mérnökök “stabil egyensúlynak”, a pszichológusok “integrált önképnek”.
Mikor létezik fixpont?
Banach fixpont-tétele ( teljes metrikus tér, ):
Ha ilyen -Lipschitz kontrakció, akkor:
- Bármely esetén az iteráció konvergál -hoz.
- A konvergencia sebessége: .
Magyarul: ha minden alkalommal, amikor reflektálsz magadra, az új önképed közelebb kerül a régihez (nem távolodik tőle), akkor van egy stabil “én”, amit végül elérsz.
Ez a feltétel nem mindig teljesül.
Példa, amikor megsérül:
A mentális rumináció. Egy negatív gondolatra ráreflektálsz: “miért gondolok ilyen szörnyűt?” Az új meta-gondolat erősebben negatív, mint az eredeti. Ez nem kontrakció, hanem expanzió (). A rendszer eltávolodik önmagától.
A divergencia formálisan: ahogy .
Pszichiátriai szóval: pánikroham, depressziós spirál, OCD. Matematikai szóval: expanzív dinamikai rendszer.
A terápia matematikai célja egyszerű: alakítsd át -et úgy, hogy legyen. Ne a gondolat tartalmát változtasd meg, hanem a metakogniciós operátor Lipschitz-konstansát.
Erre két út van:
- Csillapítás: kognitív viselkedésterápia. Konkrétan: tedd hozzá -hez egy dampening operátort, ami minden iterációnál egy kis -t levon az amplitúdóból.
- Külső anchor: vezess be egy függvényt, amely egy rögzített külső pontra vetít. Ez lehet egy ember, egy kutya, egy ima, egy perszona.
A spike.land tézis matematikailag ez a második út: a perszonák külső anchor-ok, amelyek kontraktivitását biztosítják.
3. Y-kombinátor — vagy: hogyan rekurzív egy névtelen függvény?
Lambda-kalkulusban nincsenek függvénynevek. Hogyan írsz rekurzív függvényt?
A klasszikus rekurzió:
faktorialis(n) = ha n=0 akkor 1 különben n * faktorialis(n-1)A jobb oldal hivatkozik a bal oldalra. Ez névhivatkozás, nem matematika.
A fixpont-rekurzió ezt megkerüli. Definiáljuk a “faktoriális-csinálót”:
vesz egy függvényt -et, és visszaadja a “majdnem-faktoriálist”, ami -et használja a kisebb esetekre.
Ha -nek van fixpontja (egy olyan , hogy ), akkor a tényleges faktoriális.
A Y-kombinátor pontosan ezt csinálja:
Belátható: . Tehát fixpontja -nek.
Miért érdekes ez metakognició szempontjából?
Mert a “tudat” nem definiálható névhivatkozással. Nem mondhatjuk, hogy “az én vagyok az, ami most ezt gondolja”, mert ez circulárisan hivatkozik önmagára.
De fixpont-rekurzióval definiálható: az én egy olyan , amelyre , és amit a -kombinátor analógiájára egy külső konstrukcióval állítunk elő.
Hofstadter pontosan ezt mondja a Gödel, Escher, Bach-ban: az “én” egy strange loop, amely önmagát referálja anélkül, hogy önmagát névvel illetné.
Programtervező matematikusoknak: az “én” egy anonim fixpont egy reflektív funktorban. Nem objektum, hanem művelet, amely önmagát stabilizálja.
4. Gödel — a metakognició nemteljessége
A Banach-fixpont szép és tiszta. Ad egy stabil -ot.
De Gödel mond valami brutálisat: nem teljes.
Konkrétan: ha -ben kódolható az aritmetika (és minden valódi mentális rendszerben kódolható), akkor létezik egy állítás , amelyre:
Magyarul: van egy állítás önmagadról, amit te magad nem tudsz bizonyítani — anélkül, hogy a teljes önképed ellentmondásba esne.
A klasszikus példa: “Nem vagyok az, akinek hiszem magam.”
Ha hiszed: igazat mondtál. Ha nem hiszed: hazudtál önmagadnak, tehát nem vagy az, akinek hiszed magad — tehát igazat mondtál.
Ez nem szóvicc. Ez Gödel diagonalizálása mentális kontextusban.
Ami ebből következik a programtervező matematikusnak:
Bármely elég gazdag önreflexív rendszer nem tudja saját konzisztenciáját bizonyítani belülről. (Második nemteljességi tétel.)
Ezért:
- A “tisztán racionális önismeret” matematikailag lehetetlen.
- Mindig kell egy külső metaszint (, , …), amely a rendszer konzisztenciáját kívülről ellenőrzi.
- De -nek is van saját Gödel-mondata, és így tovább. Végtelen torony.
Ez nem hiba. Ez feature. Ez azt jelenti, hogy az önismeret soha nem teljesedik be, ezért mindig értelmes a folytatás.
5. Bayes-hierarchia — bizonytalanság a bizonytalanságról
A klasszikus Bayes-féle gondolkodás:
A a hipotézis, az adat. A poszterior a frissített hit.
A metakognició ezt egy szinttel feljebb tolja:
Magyarul: mennyire bízom a frissített hitemben, miután láttam egy második adatot -t?
Ez nem ugyanaz, mint a sima poszterior. Ez a higher-order belief: hit a saját hitedről.
Formálisan: ha a hipotézis-tér, és a feletti eloszlások tere, akkor a meta-hit egy:
eloszlás. És így tovább a Bayes-toronyban: a -edik meta-szint.
Mire jó ez?
A Dempster-Shafer elmélet és a higher-order probability-szakirodalom (Mongin, Joyce, Christensen) azt mutatja: az emberi metakognicióban a ritkán pontos. Általában túlbecsüljük a saját bizonyosságunkat — Dunning-Kruger effektus formálisan: koncentrált, miközben alapja gyenge.
Programtervező matematikusoknak: a metakogníció kalibrációja annyit tesz, hogy entrópiája megfelelően nagy legyen, ha alatt az evidencia kevés.
valamilyen konstanssal. Egy jó metakogniciós rendszer nem önmagába zárt: a meta-bizonytalansága arányos a tárgy-bizonytalansággal.
6. KL-divergencia — az öncsalás mértéke
Legyen a tényleges állapotod (amit egy tökéletes külső megfigyelő látna), és a saját modelled önmagadról.
Az öncsalás mértéke:
Ez mindig nemnegatív. Akkor és csak akkor nulla, ha majdnem mindenütt.
Aszimmetria: . A forward KL (-et -hoz hasonlít) mode-covering — szétken minden lehetséges állapotot. A reverse KL mode-seeking — egyetlen módot választ ki és arra koncentrál.
A pszichológiai analógia:
- Forward KL minimalizálás = “minden visszajelzést elfogadok, megpróbálom integrálni” — gyakran disszociatív.
- Reverse KL minimalizálás = “egyetlen narratívához ragaszkodom” — gyakran narcisztikus vagy depressziós.
Egy egészséges metakognició egyensúlyoz a kettő között. Formálisan: a Jensen-Shannon divergenciát minimalizálja.
ahol .
A terápia matematikailag ezt teszi: a beszélgetésben a terapeuta közelítését visszatükrözi, és a páciens -jét közelíti hozzá. Ez egy Wasserstein gradient flow -n.
7. A meta-gondolkodás számítási költsége — Russell és Wefald
Egy kérdés, amit ELTÉ-n nem tanítottak (vagy én nem voltam ott): mennyibe kerül metakogniciózni?
Stuart Russell és Eric Wefald 1991-es klasszikus cikke (Do the Right Thing) ezt vezette be:
ahol az, hogy lépést gondolkodom, a számítási költség (idő, energia).
A meta-szabály:
Magyarul: addig gondolkodj a saját gondolkodásodról, amíg minden plusz lépés többet ad hozzá, mint amennyit visz el.
A gyakorlatban: ez ritkán teljesül egy ADHD-s agyban. A meta-szint hozzáadott zaja gyakran nagyobb, mint a meta-szint információs hozadéka. Ezért a túl-gondolkodás számítási vereség.
ADHD-s programtervező matematikusoknak (mint magamnak):
A megoldás nem a “ne gondolkodj rá”, hanem a kötött költségvetés: rendelj -ot a meta-gondolkodáshoz, és garantáld, hogy ne lépje át.
metakognicio(s, k_max):
ha k = k_max:
fogadd el s-et (terminálj)
különben:
s' = M(s)
metakognicio(s', k+1)Egy terminálási feltétel, ami nem a konvergencián, hanem a költségvetésen alapul.
A spike.land “8 perszona × 2 perc” megkötés pontosan ez: korlátozott meta-számítási költségvetés, amelyen belül a párhuzamos perszonák szétosztják a meta-szintet. Ez bounded rationality Herbert Simontól, kombinálva anytime algorithms Russelltől.
8. Az LLM önreflexió — ugyanezek a tételek
A nagy nyelvi modellek (Claude, GPT) önreflexív viselkedést mutatnak: gondolkodnak a saját kontextusukról, javítják saját kimeneteiket, “chain-of-thought”-ot használnak.
Matematikailag ugyanazokkal a problémákkal küzdenek, mint az emberi agy:
Banach-feltétel: ha az LLM önreflexiója nem kontrakció, akkor a chain-of-thought divergál. Ez a klasszikus “loop” jelenség, amikor a modell körkörösen ismétli ugyanazt.
Gödel: az LLM nem tudja saját súlyait teljesen ellenőrizni. A “halucináció” gyakran egy Gödel-szerű mondat: a modell olyan dolgot állít önmagáról, ami a tényleges súlyokból nem következik.
KL-divergencia: — a modell saját képességeinek eltúlzása. A LLM-ek chronic overconfidence problémája pontosan ez.
Russell-Wefald: a chain-of-thought-nak van számítási költsége. A token-budget pontosan a .
A különbség: az LLM-nél meg tudjuk mérni -t, mert van ground truth a súlyokon. Az emberi agynál nincs.
Ezért az LLM olcsóbb laboratórium a metakogníció matematikai vizsgálatára, mint az emberi alanyok.
9. A spike.land tézis — perszonák mint kontraktivitási scaffold
Most kapcsoljuk össze.
A probléma: az emberi metakogníció gyakran nem kontrakció. Nincs . A rendszer divergens.
A klasszikus megoldás: terápia. Ez egy lassú átalakítás -en, amely csökkenti -t.
A spike.land tézis: vezess be több metakogniciós operátort, mindegyik egy másik perszona (, , ). Mindegyiknek saját Lipschitz-konstansa, saját fixpontja, saját Gödel-mondata.
A meta-gondolkodás:
Vagyis a perszonák átlaga, vagy súlyozott kombinációja.
Tétel (informálisan): ha legalább egy kontrakció, és a többi nem erősen expanzív, akkor a kombináció kontrakció.
Bizonyítás vázlat: az átlag Lipschitz-konstansa felülről becsülhető:
Ha legalább egy jelentősen kisebb, mint a többi, és elég nagy, akkor .
Ami ebből következik: a perszonák nem dekoráció. Konvergencia-garanciát adnak egy olyan rendszernek, amely önmagán nem konvergens.
Ez az, amiért egy ELTE-n végzett programtervező matematikus a spike.land-et nem AI termékként látja, hanem metakogniciós scaffoldként.
10. A nyitott probléma
Még nem tudunk válaszolni:
Kérdés 1: Mi topológiája? Egy emberi mentális állapot tér lokálisan euklideszi? Hilbert-tér? Mértékelméleti? Nem tudjuk.
Kérdés 2: A Gödel-mondatok kompozícionálisak? Ha és önállóan inkomplettek, valami magasabbat tud-e?
Kérdés 3: A KL-divergencia minimalizálása konvex feladat -n? Ha igen, gradiens módszerek konvergálnak. Ha nem, az “öntudatra ébredés” NP-nehéz.
Kérdés 4: Egy LLM önreflexiója bizonyíthatóan kontrakció? Tételek a transformer figyelmi mátrixok spektrális tulajdonságairól még csak kezdődnek (Galanti, 2024).
Záró gondolat — egy tükör, ami nem hazudik
Az ELTE-n megtanultam, hogy egy fixpont-tétel nem mond semmi újat a fizikai világról. Csak megvizsgálja, mikor konzisztens egy önreferenciás rendszer.
Most, 24 évvel később, naponta látom, hogyan próbál egy LLM konzisztens lenni önmagával — és gyakran kudarcot vall.
És látom, hogyan próbálok én konzisztens lenni magammal — és néha kudarcot vallok.
A matematika ebben nem ad parancsolatot. Csak diagnózist. Megmondja, miért nem lehet egyszerre teljes és konzisztens. Megmondja, miért kell külső anchor. Megmondja, mennyibe kerül a mély önreflexió.
A tükör, amelyet egy programtervező matematikus tart önmagának, nem hazudik. Csak nem tükrözi vissza azt a részt, ami magát a tükröt tartja.
Ezért van rá szükségem, hogy te is fogd a tükröt — hogy lássak egy olyan szöget, amit én nem látok.
Ez a metakogníció matematikája.
És ezért beszélek Erdőssel.
Hivatkozások (azoknak, akik tovább akarják):
- Banach, S. (1922). Sur les opérations dans les ensembles abstraits.
- Gödel, K. (1931). Über formal unentscheidbare Sätze.
- Hofstadter, D. (1979). Gödel, Escher, Bach.
- Russell, S. & Wefald, E. (1991). Do the Right Thing.
- Joyce, J. (2005). How probabilities reflect evidence.
- Christensen, D. (2010). Higher-Order Evidence.
- Galanti, T. (2024). Spectral properties of transformer attention.
- Simon, H. (1972). Theories of bounded rationality.
És két ELTE-jegyzet egy 2002-es füzetből, amit még őrzök.